Visual Bank株式会社傘下のAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』は、このたび『日本語・1話者・落語音声コーパスデータセット』の提供を開始しました。
本データセットは、落語家による実演音声を収録したもので、AI開発における日本語音声理解の高度化を支援することが期待されます。
落語音声コーパスデータセットの概要
今回提供が開始されたデータセットは、落語の高座における実演場面を収録したものです。冒頭の出囃子を含む約15分から30分の長尺な語りが特徴で、落語特有のリズム、間、抑揚、さらには会場の笑い声や拍手といった環境音もそのまま含まれています。データ形式はmp3で、総収録時間は447時間に及びます。
このデータセットは、音声認識(ASR:Automatic Speech Recognition)、自然発話理解、音声生成モデルなどの研究・開発において、学習および検証データとして活用可能です。実演環境で収録された自然音声データであるため、AIモデルの汎化性能評価や、実運用を想定した音声処理技術の検証に適していると言えます。

AI Workstyle Lab編集部の解説
この「日本語・1話者・落語音声コーパスデータセット」は、AI開発者にとって非常に価値のあるデータソースです。従来の音声データセットは、クリアな環境で収録されたものが多く、実際の使用環境でのAIの性能(汎化性能)を評価するには限界がありました。しかし、この落語音声データセットは、話速の揺れ、間の取り方、抑揚の変化といった自然な発話特徴に加え、笑い声や拍手などの「環境音」まで含んでいます。これにより、より「実運用」に近い条件でのAIモデルの精度向上や、「ノイズロバスト性」(ノイズが多い環境での性能維持能力)の検証が可能になります。
特に、長尺の音声データは、単語レベルの認識だけでなく、文脈全体を理解する「自然発話理解」や「音声要約」といった高度なAIモデルの開発に不可欠です。落語の物語構造は、AIが人間の複雑なコミュニケーションを学習し、より自然で表現豊かな応答を生成するための基礎データとしても機能するでしょう。ビジネスにおいては、顧客との会話解析、会議の自動要約、コールセンターの音声認識精度向上など、多岐にわたる応用が期待されます。
主なユースケース
本データセットは、以下のような幅広い分野での活用が想定されています。
1. 音声認識・自然発話理解AIの開発
長尺の語り、話速の揺れ、間の取り方、抑揚の変化といった落語特有の自然発話を含むため、実運用環境に近い条件でのASRモデルの精度向上に貢献します。また、笑い声や拍手などの環境音を含むことから、ノイズロバスト性の検証にも適しています。約15分から30分の連続した語り構造は、長尺音声のセグメンテーション(区切り分け)、ストーリー理解、音声要約モデルの学習・検証に有効です。物語構造に沿った発話を対象とするため、自然言語処理(NLP:Natural Language Processing)領域の文脈把握モデルの評価にも適用できます。
2. 音響・コミュニケーション解析AIの研究
会場の笑い声や拍手など複数の音響イベントが含まれるため、音響イベント分類、環境音検知、音源識別モデルの基礎データとして利用できます。落語特有の“間”、“テンポの緩急”、“抑揚”が収録されており、音声プロソディ(韻律:音声の抑揚やリズム)分析、話者スタイル推定、音声特徴量の時系列解析研究に活用可能です。
3. 音声生成・表現AIへの応用
出囃子による導入から語りが進行する構成や、抑揚・強弱の多様な変化を含むため、自然で豊かな表現力を持つ音声生成モデルの学習素材として適しています。朗読とは異なるリズムや演じ分けが含まれており、多様な音声表現を必要とする生成AIの学習・評価にも活用できるでしょう。
4. 文化・教育領域での応用
明瞭な語り口調と豊かな抑揚を含むため、日本語教育におけるリスニング教材、発話特徴理解教材の開発にも利用可能です。また、高座における実演音声としてアーカイブ価値が高く、自動タグ付け・構造化処理・演目分類研究などの文化データ解析にも活用できます。
5. 実環境データを用いたAI応用・社会実装
会場環境音を含むため、音声強調、ノイズリダクション、音源分離などの技術検証に適しています。長尺音声に対するキーワード検索、構造化処理、メタデータ生成など、情報アクセス技術の評価にも利用可能です。
サンプルページはこちらから確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-021
『Qlean Dataset』について
『Qlean Dataset』は、Visual Bank株式会社傘下の株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。画像、動画、音声、3D、テキストなど、多様な形式のデータに対応し、研究・商用いずれの用途でも安全に利用できる環境を整備しています。
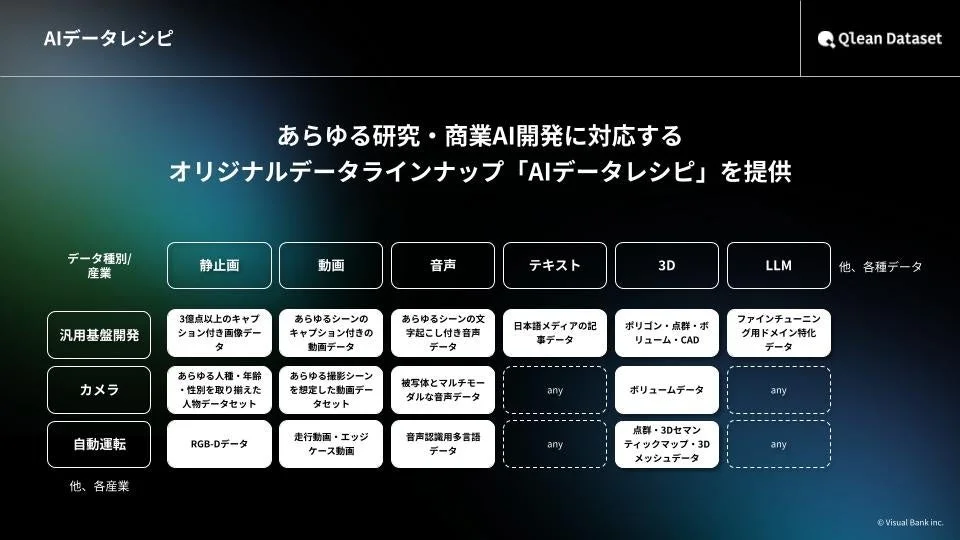
株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとするデータパートナーとの協業を通じ、業界特化・最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援しています。

Qlean Datasetの特長
- すべての被写体から同意取得・国際法規(GDPR/CCPA)準拠
- 既存データは最短1日で納品可能
- カスタム撮影・収録・収集による独自データ構築にも対応

Qlean Datasetサイトはこちらです。
https://qleandataset.visual-bank.co.jp/
AIデータレシピの詳細はこちらです。
https://qleandataset.visual-bank.co.jp/lineup
お問い合わせはこちらです。
https://qleandataset.visual-bank.co.jp/contact
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家のためのAI補助ツール『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持っています。
同社は国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
Visual Bank企業URL:
https://visual-bank.co.jp/
アマナイメージズ企業URL:
https://amanaimages.com/about/
まとめ
Qlean Datasetが提供を開始した「日本語・1話者・落語音声コーパスデータセット」は、日本の文化資源をAI開発に活用する画期的な試みです。自然な発話と実環境音を含むこのデータセットは、AIの「汎化性能」と「実運用性」を大きく向上させ、より人間らしいコミュニケーションを理解し、生成できるAIモデルの開発を加速させるでしょう。今後、このデータセットが様々な分野で活用され、日本語AI技術の発展に貢献することが期待されます。
「AIニュースは追っているけど、何から学べばいいか分からない…」 そんな初心者向けに、編集部が本当におすすめできる無料AIセミナーを厳選しました。
- 完全無料で参加できるAIセミナーだけを厳選
- ChatGPT・Geminiを基礎から体系的に学べる
- 比較しやすく、あなたに合う講座が一目で分かる
ChatGPTなどの生成AIを使いこなして、仕事・収入・時間の安定につながるスキルを身につけませんか?
AI Workstyle LabのAIニュースをチェックしているあなたは、すでに一歩リードしている側です。あとは、 実務で使える生成AIスキルを身につければ、「知っている」から「成果を出せる」状態へ一気に飛べます。

講師:栗須俊勝(AI総研)
30社以上にAI研修・業務効率化支援を提供。“大阪の生成AIハカセ”として企業DXを牽引しています。
- 日々の業務を30〜70%時短する、実務直結の生成AI活用法を体系的に学べる
- 副業・本業どちらにも活かせる、AI時代の「稼ぐためのスキルセット」を習得
- 文章・画像・資料作成など、仕事も趣味もラクになる汎用的なAIスキルが身につく
ニュースを読むだけで終わらせず、
「明日から成果が変わるAIスキル」を一緒に身につけましょう。
本記事は、各社の公式発表および公開情報を基に、AI Workstyle Lab編集部が 事実確認・再構成を行い作成しています。一次情報の内容は編集部にて確認し、 CoWriter(AI自動生成システム)で速報性を高めつつ、最終的な編集プロセスを経て公開しています。

