GMOインターネット、NVIDIA B300 GPU搭載環境の性能を実証
GMOインターネット株式会社は、同社の「GMO GPUクラウド」において、NVIDIA H200 Tensor コアGPU(以下、H200 GPU)とNVIDIA HGX B300 AI インフラストラクチャ(以下、B300 GPU)を導入したGPUクラウドサービスの性能特性を検証し、その結果を公開しました。
この検証は、生成AI開発から運用までの実用性と演算性能の両面を評価するため、以下の3つのベンチマークを実施して行われました。
- 大規模言語モデル(LLM)の学習ベンチマーク: 学習効率と演算速度を評価
- vLLM bench throughputによる推論ベンチマーク: 単位時間あたりに生成可能なトークン量(処理スループット)を評価
- HPL Benchmarkによるベンチマーク: 高精度な数値計算の処理能力を評価
これらのベンチマークにより、生成AIの開発から運用までの実用性能と演算性能の両面から、B300 GPUとH200 GPUの各々の特性が検証され、ワークロードに応じた最適なGPUを選択するための参考情報が提供されています。
ベンチマーク結果の概要
今回の検証では、生成AIワークロードにおいて、B300 GPUはH200 GPUと比較して学習で約2倍、推論では約2.5倍の処理性能を発揮することが確認されました。これは生成AI関連のタスクにおいて、B300 GPUがH200 GPUを大きく上回る性能を持つことを示しています。
一方、スーパーコンピュータの性能評価に用いられるHPL Benchmarkでは、B300 GPUはH200 GPUのわずか2.1%(約47分の1)の性能にとどまりました。この結果は、B300 GPUが生成AIワークロードに特化した高い性能を有している一方で、科学技術計算など計算結果の正確性を求めるユースケースにおいては、依然としてH200 GPUが適している可能性を示唆しています。
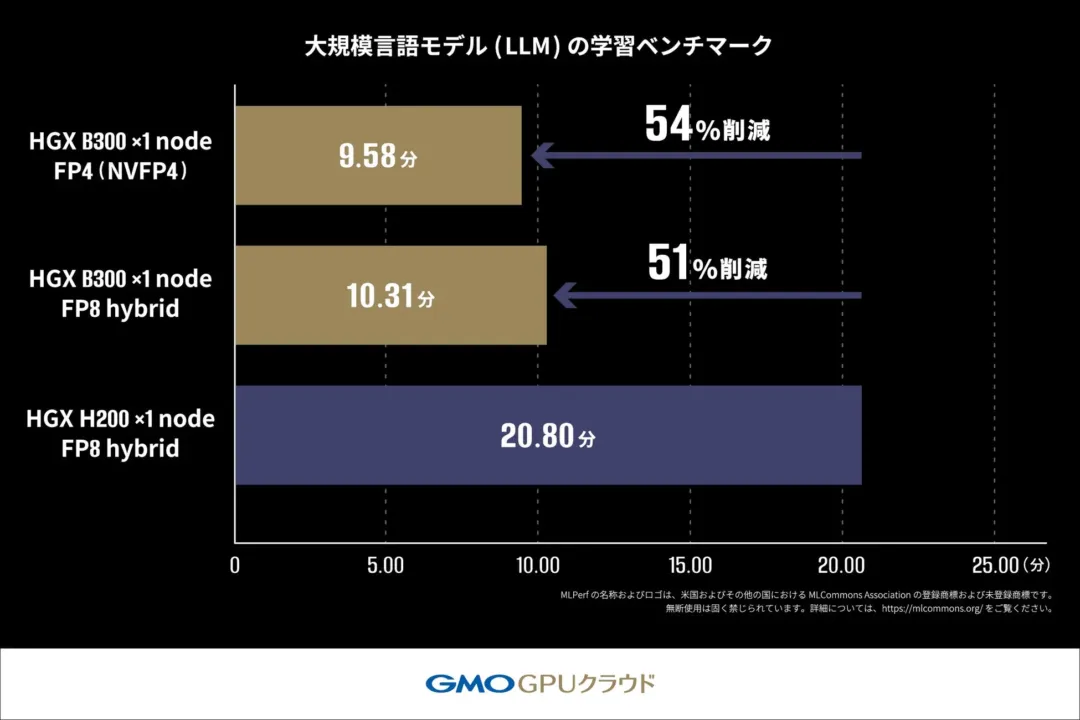
大規模言語モデル(LLM)の学習ベンチマーク
MLPerf ® Training v5.1のルールに従い、Llama2 70Bモデルを用いたLoRAファインチューニングにかかる学習時間を測定しました。
H200 GPU搭載機材では20.80分かかっていた学習時間が、B300 GPU搭載機材では10.31分で完了し、約2倍の速度で処理が完了しています。さらに、NVIDIA Blackwellアーキテクチャより新たに対応したFP4(4ビット浮動小数点演算)を用いた測定では、FP8 hybrid(8ビット浮動小数点演算と高精度演算を組み合わせた混合精度学習手法)を使用した学習よりもさらに短い時間で処理が完了しており、FP4の高い演算性能を活かすことで学習でもその恩恵を受けることができる可能性が示されています。
-
MLPerf ®: MLCommons Associationが管理する機械学習システムの性能測定における国際的なベンチマーク標準です。詳細は www.mlcommons.org を参照ください。
-
LoRAファインチューニング: 大規模言語モデルを効率的に学習させる手法です。
-
クロスエントロピー損失: AIモデルの予測精度を測定する指標で、値が小さいほど高精度なモデルであることを示します。
vLLM bench throughputによる推論ベンチマーク
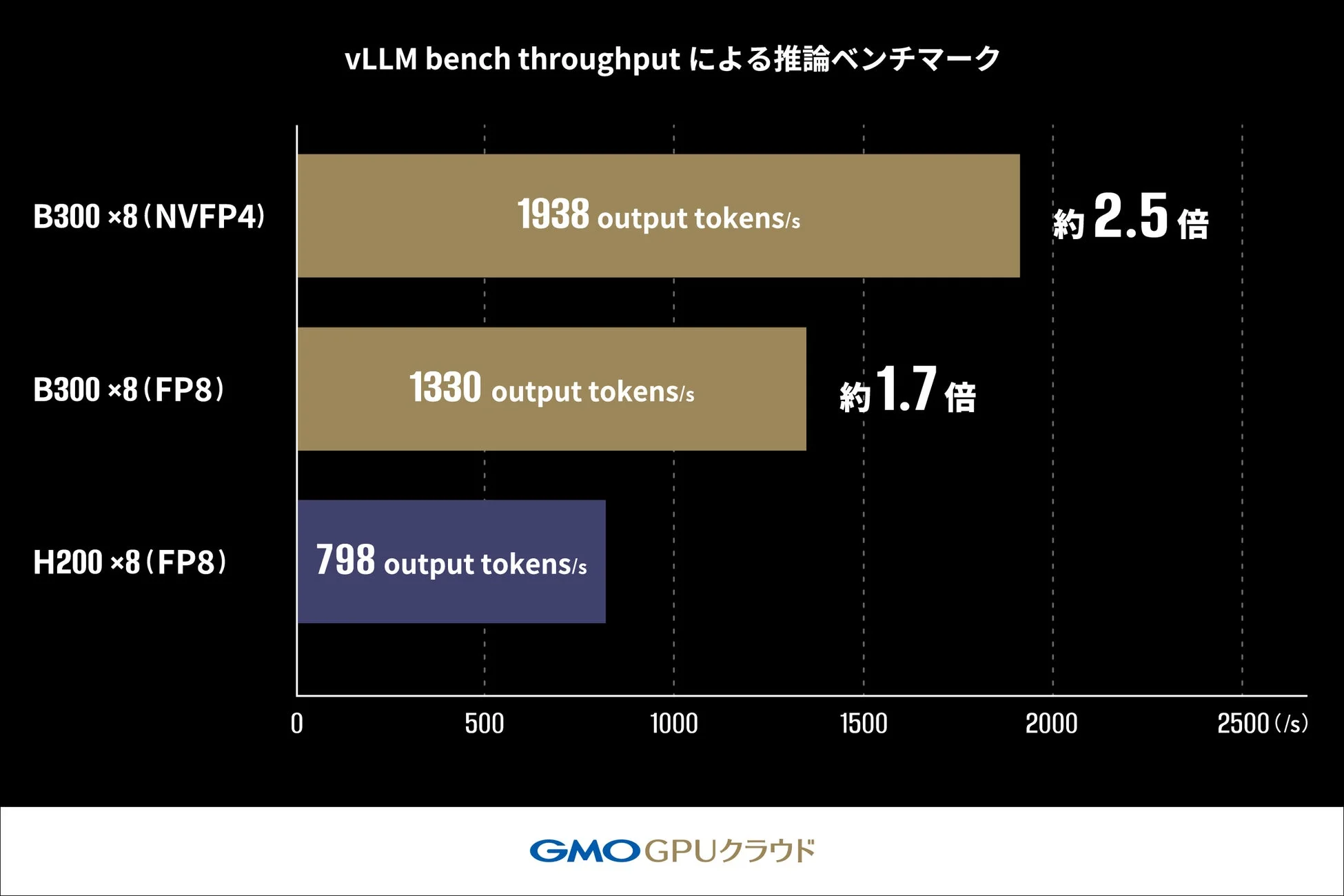
vLLMのOffline Throughput Benchmarkを用い、Llama-3.1-405B-Instructモデルの推論スループットを測定しました。これは、LLM推論のバッチ処理におけるH200 GPUおよびB300 GPUが1秒あたりに生成できる出力トークン数(output tokens/s)の最大処理能力を比較するものです。
このベンチマークにおいて、H200 GPU(FP8)構成では798 tokens/sであったスループットが、B300 GPU(FP8)構成では約170%(約1.7倍)の1330 tokens/sまで向上しました。さらに、FP4(NVFP4)を適用した構成では1938 tokens/sを達成し、H200 GPU構成に対し約250%(約2.5倍)の性能向上を確認しています。この結果から、FP4の活用が大規模モデルの推論パフォーマンスを向上させるための有力な手段の一つであることがうかがえます。
-
vLLM bench throughput: 大規模言語モデル推論エンジン「vLLM」のベンチマークツールです。
-
Offline Throughput Benchmark: vLLM bench throughputで実行するベンチマークモードで、バッチ処理における最大スループットを測定します。
HPL Benchmarkによるベンチマーク
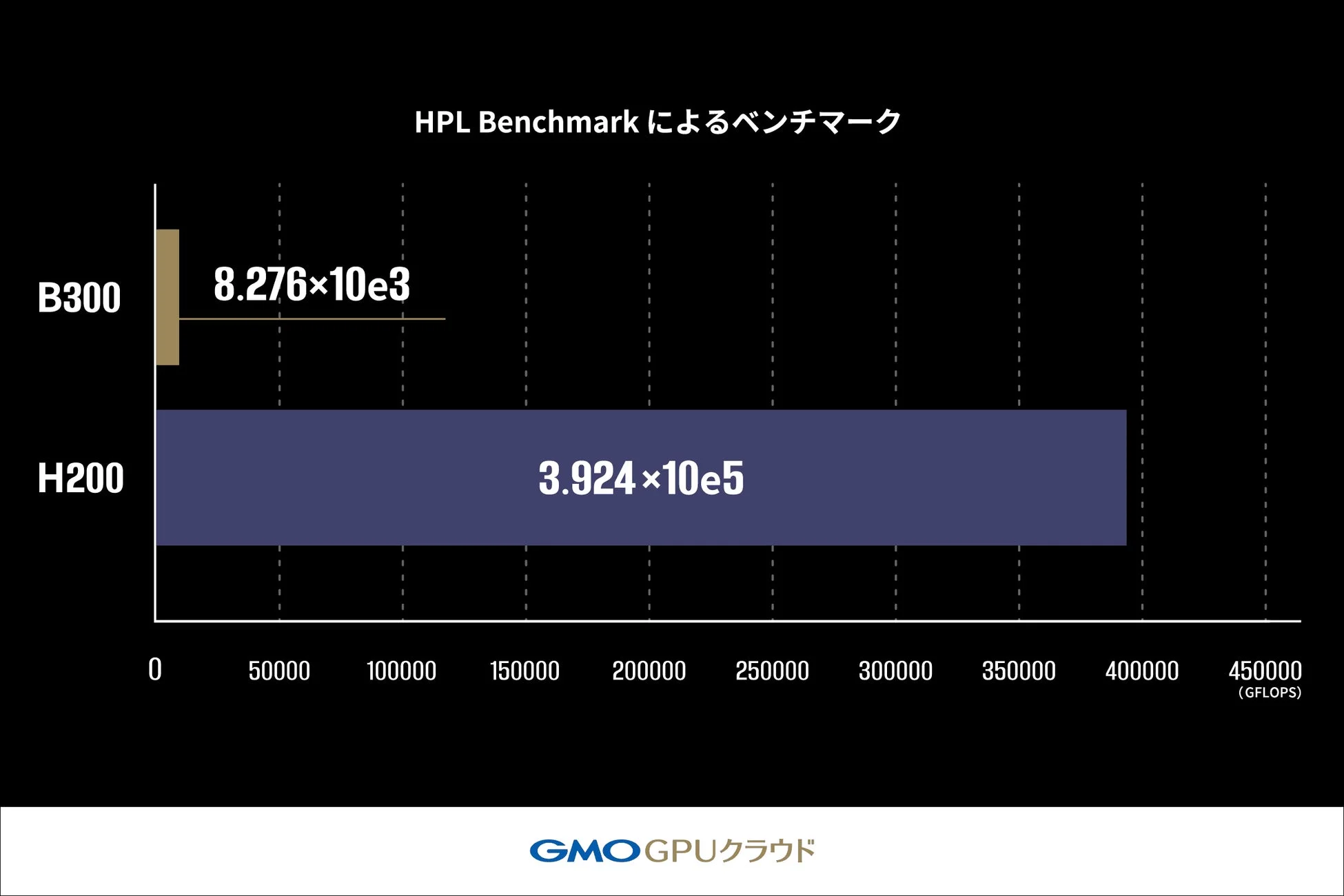
HPL Benchmarkを用いて、B300 GPU搭載機材およびH200 GPU搭載機材のLINPACK性能を比較しました。HPL Benchmarkでは、浮動小数点演算性能を測定し、1秒間に実行できる演算回数をGFLOPS(10億回の浮動小数点演算/秒)という単位で算出します。
その結果、B300 GPU搭載機材の性能はH200 GPU搭載機材の2.1%(約47分の1)となりました。これは、B300 GPUがAIワークロードに最適化された設計である一方、高精度演算(FP64)が求められる科学技術計算においては、H200 GPUが依然として有用であることを示唆しています。
-
HPL Benchmark: スーパーコンピュータの性能評価に用いられる国際標準ベンチマークです。
-
LINPACK性能: 複雑な数式を正確に解く計算能力で、科学技術計算での性能を示す指標です。
実施環境
| H200 | B300 | |
|---|---|---|
| サーバモデル | DELL PowerEdge XE9680 | DELL PowerEdge XE9780 |
| CPU | 第4世代インテル® Xeon® スケーラブル・プロセッサー・ファミリー | 第6世代インテル® Xeon® スケーラブル・プロセッサー・ファミリー |
| ディスク構成 | NVMe 7.68TB x4 | NVMe 3.5TB x8 |
| GPU | NVIDIA HGX H200 | NVIDIA HGX B300 |
GMOインターネットのコメントと今後の展開
GMOインターネットのインフラ・運用本部 プロジェクト統括チーム エグゼクティブリード 佐藤嘉昌氏は、今回のベンチマーク結果がB300 GPUとH200 GPUの性能特性の違いを示す一つのデータとして参考になるだろうと述べています。「GMO GPUクラウド」は、顧客の開発目的や利用用途に寄り添い、より効率的に計算資源を活用できるよう、技術協力を継続し、AI開発環境における技術向上を支援していく方針です。
今後は、「GMO GPUクラウド」を通じて、生成AI分野に取り組む企業や研究機関に向け、ワークロード特性に応じて最適なGPUクラウドサービスを選択できる柔軟な計算環境を提供していくとのことです。今回の性能検証結果を踏まえ、生成AIの学習・推論といったAIワークロードに強みを持つB300 GPUと、高精度な数値計算を必要とする用途に適したH200 GPUを、顧客のユースケースに応じて柔軟に組み合わせて提案していきます。これにより、開発期間の短縮とコスト低減に貢献し、国内AI産業の発展を促進するとしています。
「GMO GPUクラウド」とは
「GMO GPUクラウド」は、NVIDIA H200 Tensor コアGPUを搭載し、国内初となる高速ネットワークNVIDIA Spectrum-Xと高速ストレージを実装しています。
2024年11月に発表された世界のスーパーコンピュータ性能ランキング「TOP500」では、世界第37位・国内第6位にランクインし、商用クラウドサービスとしては国内最速クラスの計算基盤を提供しています。さらに、2025年6月には電力効率を競う世界ランキング「Green500」にて世界第34位・国内第1位を獲得し、高性能と省電力性の両立が国際的に評価されました。加えて、2025年12月にはNVIDIAの次世代GPU「NVIDIA Blackwell Ultra GPU」を搭載した「NVIDIA HGX B300」のクラウドサービス提供を開始しています。
詳細はこちら: https://gpucloud.gmo/
AI Workstyle Lab編集部コメント
今回の性能検証は、企業がAIプロジェクトを進める上で非常に重要な指針となります。生成AIモデルの開発や運用を主眼に置く企業であれば、学習・推論で圧倒的な性能を発揮するB300 GPUがコストパフォーマンスと開発速度の両面で大きなメリットをもたらすでしょう。一方で、製薬や物理シミュレーションなど、極めて高い精度が求められる科学技術計算の分野では、H200 GPUが引き続き最適解となります。各GPUの特性を理解し、ワークロードに合わせた適切な選択をすることで、AI投資のROIを最大化し、ビジネスの競争力向上に直結するはずです。
「AIニュースは追っているけど、何から学べばいいか分からない…」 そんな初心者向けに、編集部が本当におすすめできる無料AIセミナーを厳選しました。
- 完全無料で参加できるAIセミナーだけを厳選
- ChatGPT・Geminiを基礎から体系的に学べる
- 比較しやすく、あなたに合う講座が一目で分かる
ChatGPTなどの生成AIを使いこなして、仕事・収入・時間の安定につながるスキルを身につけませんか?
AI Workstyle LabのAIニュースをチェックしているあなたは、すでに一歩リードしている側です。あとは、 実務で使える生成AIスキルを身につければ、「知っている」から「成果を出せる」状態へ一気に飛べます。

講師:栗須俊勝(AI総研)
30社以上にAI研修・業務効率化支援を提供。“大阪の生成AIハカセ”として企業DXを牽引しています。
- 日々の業務を30〜70%時短する、実務直結の生成AI活用法を体系的に学べる
- 副業・本業どちらにも活かせる、AI時代の「稼ぐためのスキルセット」を習得
- 文章・画像・資料作成など、仕事も趣味もラクになる汎用的なAIスキルが身につく
ニュースを読むだけで終わらせず、
「明日から成果が変わるAIスキル」を一緒に身につけましょう。
本記事は、各社の公式発表および公開情報を基に、AI Workstyle Lab編集部が 事実確認・再構成を行い作成しています。一次情報の内容は編集部にて確認し、 CoWriter(AI自動生成システム)で速報性を高めつつ、最終的な編集プロセスを経て公開しています。

